Implementation of Axiomatic Retrieval Functions in Lucene
Last Updated: August 20, 2009
Introduction
Lucene is a popular open-source IR tookit,
which has been widely used in many search related applications. However, the default similarity
function currently implemented in Lucene (i.e., version 2.4.1 or earlier) often perform WORSE than
the state of the art retrieval functions.
An improved retrieval function would enable all the applications based on Lucene such as
Nutch to achieve higher search accuracy. Thus, it is important
to implement the state of the art retrieval functions in Lucene.
Axiomatic approaches to IR has been proposed to develop effective and robust retrieval functions.
Our previous study shows that
the derived retrieval functions are more robust than other state of teh art retrieval functions with
comparable optimal performance. The following function (F2-EXP) is one of the best performing functions
derived using axioamtic approach.
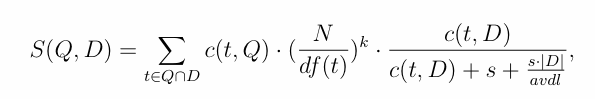
Here are the notations used in the functions.
- S(Q,D): the relevance score of document D for query Q.
- c(t,Q): the count of term t in query Q.
- c(t,D): the count of term t in document D.
- df(t): the number of documents containing term t.
- |D|: is the length of document D.
- avdl: is the average document length in the collection.
- k and s: retrieval parameters. Setting them to default values (i.e., k=0.35 and s=0.5) can often lead to near-optimal performance.
We have implemented the F2-EXP axiomatic retrieval function using Lucene and compared the performance of these two functions using
three representative TREC collections. This page briefly describes how we implemented the aximoatic
retrieval function and how to integrate the code with Lucene for your own search task.
You can download our report of the evaluating the default similarity function of Lucene here.
Implementation and Download
We integrated the axiomatic retrieval function into Lucene toolkit through the implementation of two new classes, i.e., AXTermQuery
and AXTermScorer, which are the extended classes of TermQuery and TermScorer respectively. Unlike the default similarity function,
the axiomatic retrieval funtion needs to compute the average document length of the collection. Instead of modifying the current
index structure of Lucene, we provide a code (BuildIndex) that would build the index using Lucene and then compute and store the
information of avdl in a seperate file (i.e., LengthInfo.txt) under the index directory. We also provide a code (RetAXEval) that
could read the Lucene index as well as average document length information and then run the retrieval process using the implemented
axiomatic retrieval functions.
You can download the source codes of our implementation for two different versions of Lucene here:
Please follow the instruction to run the retrieval using the axiomatic retrieval functions:
- Download the current version of Lucene (lucene-2.4.1), and use "ant" to compile.
- Download the provided source codes of our implementation, and unzip the file.
- Compile the download source codes: "javac -classpath LUCENECLASSPATH: *.java", where LUCENECLASSPATH is the path to the lucene classes, e.g., lucene-2.4.1/build/classes/java/.
- Build the index: "java BuildIndex ". is the file name of the data collection. It needs to be in TREC format. You can modify the code to process the files in other formats. The index will be written under "index" directory.
- Retrieve the documents: "java RetAXEval k s". is the file of query. The format is "queryID"+"\t"+"QUERYTERMS". Again, you can modify the code for other formats. k and s are two retrieval parameters of F2-EXP. The suggested values are: k=0.35 and s=0.5. is the output file with three columns: "queryID" "DocumentID" and "relevance score". Note that the index needs to be stored under "index" directory.
Contact Information
If you have any questions, please feel free to email us (hfang AT ece.udel.edu).